Thanks to Deep Learning, Computer Vision is one of the areas that has been rapidly advancing in the recent times. The advancements in Computer Vision with Deep Learning has been constructed and perfected primarily over the time due to one algorithm - the Convolutional Neural Network.
A Convolutional Neural Network (CNN/ConvNet) is a Deep Learning Algorithm which can take in input image, assign various weights to the different aspects in that image and hence on learning, be able to differentiate one image from another.
Let us look into the basic steps required for a CNN Model.
The computer sees an image as an array of pixels, which depends on the image resolution. As discussed in my previous blogs, the array mainly consists of the RGB pixels.
For eg, lets say the input image is the following RGB Matrix :
 Here this is a 4x4x3 RGB image matrix where the height of the image is of 4 pixels, width is 4 pixels, and the 3 refers to the RGB values. This is just for learning purpose, but practically an image consists of thousands of pixels, so imagine how computational extensive the process will get.
Here this is a 4x4x3 RGB image matrix where the height of the image is of 4 pixels, width is 4 pixels, and the 3 refers to the RGB values. This is just for learning purpose, but practically an image consists of thousands of pixels, so imagine how computational extensive the process will get.




A Convolutional Neural Network (CNN/ConvNet) is a Deep Learning Algorithm which can take in input image, assign various weights to the different aspects in that image and hence on learning, be able to differentiate one image from another.
Let us look into the basic steps required for a CNN Model.
The Input Image
For eg, lets say the input image is the following RGB Matrix :
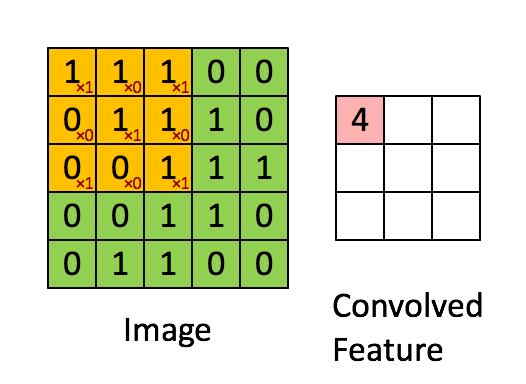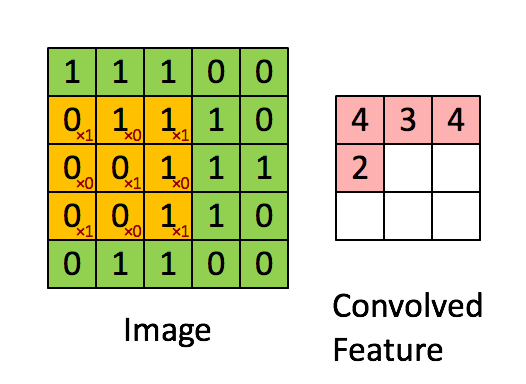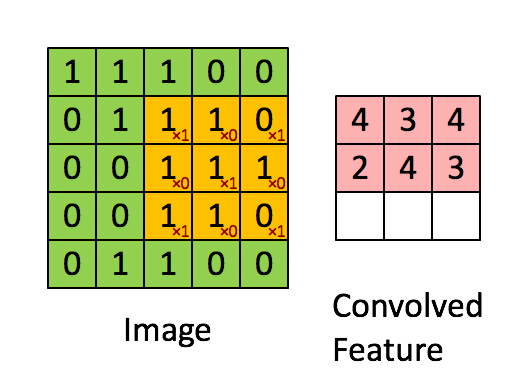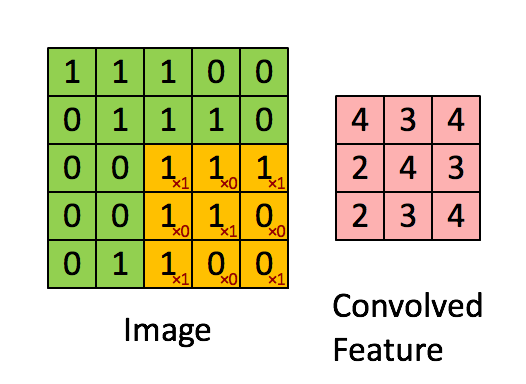
The Convolution Layer
This is the first layer which is used to extract features from the input image. This operation takes in two inputs The image matrix and a filter. In this operation, small squares of the image matrix are convolved with the filter to preserve the relationship between the pixels.
Here there takes place the convolution between a 5x5 image matrix and a 3x3 filter by taking 3x3 squares(also called the Feature Map) from the image matrix serially. This operation helps to retain the image features and also significantly reduce the matrix size while maintaining the image properties.
Padding
In order to build deep neural network, one of the modification which we make to the basic convolutional operation is padding. We face 2 downsides in the normal convolutional process:
1. Every time we apply a convolutional operator, our image shrinks. And after a few operations, the image might become really very small. There might be times when we don't want our image to shrink every time we convolve it to detect a feature.
2. If we look at the pixels at the edges, we will notice that these pixels are touched only once and are present in only one of the Feature Maps of the image matrix during the entire convolution process. While the pixels in the middle , there are a lot of the Feature Maps which overlap those pixels multiples of times. So we might be throwing away a lot of information at the edge of the image.
Hence to overcome these problems, we pad our image with zeros on all sides.
Strides
We refer to the number of rows and columns traversed by the filter per convolution as the Stride. If the stride is 1, the filter shifts 1 pixel at a time, when the stride is 2, the filter shift 2 pixels at a time and so on. The filter traverses an entire row with a certain stride till it parses the complete width. Then it moves down with the same stride, and again traverses the entire width and this continues till it reaches the end of the image matrix.
Non Linearity
The ReLU function introduces non-linearity in our ConvNet. As talked in the previous blogs, ReLU gives the output as f(x) = max(0,x). The ReLU function is mainly used to bring non-linearity since it is better performance-wise.
Pooling Layers
ConvNets often use pooling layers to reduce the size of the representation, to speed the computation as well as make some of the features detected more robust. The commonly used Pooling are Max Pooling and Average Pooling.
- Max Pooling : In this pooling operation, we select the maximum element from the region which the filter convolves with the image matrix.
- Average Pooling: In this pooling operation, we select the average of all the elements from the region which the filter convolves with the image matrix.
Fully Connected Layer
A fully connected layer basically takes the output of the convolution and the pooling and predicts the best label to describe the image. This layer takes the output of all the previous layers and flattens them into a single column vector that can be used as an input for the upcoming stages. The final and the last fully connected layer gives the probabilities of each label in the input image.
Now after applying backpropagation and helping the model to learn by itself, through a series of epochs the model will be able to classify the image using the Softmax Classification Technique.
So hence to summarize the complete flow of CNN to process an input image and classify and predict objects based on values, we can represent it through the following diagram:
Convolutional Neural Networks has accomplished astonishing achievements across a variety of domains and has been a key in strategizing algorithms which have and will have the potential to power AI as a whole in the envisaged future.
Comments
Post a Comment